Token-based Audio Inpainting via Discrete Diffusion
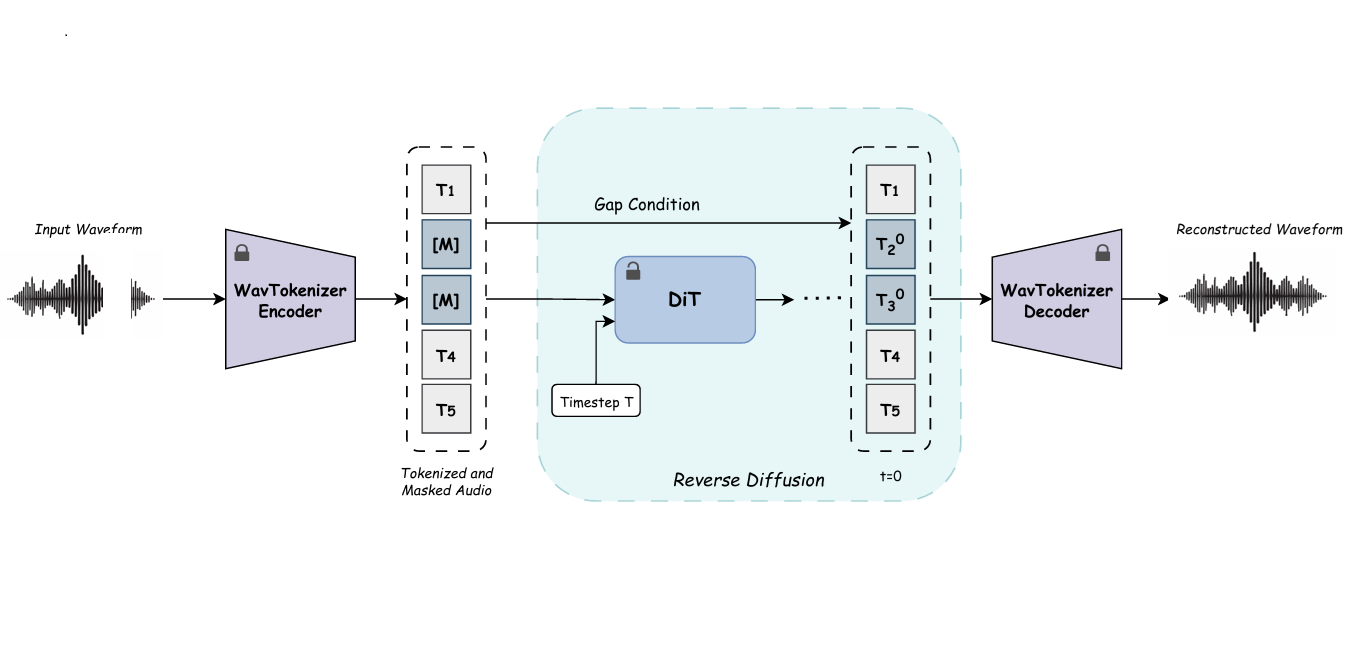
We introduce our method: Audio Inpainting using Discrete Diffusion Model (AIDD), a novel approach for audio inpainting that applies discrete diffusion modeling over tokenized
representations of audio. Using a pretrained WavTokenizer and a discrete diffusion model, AIDD reconstructs
missing audio segments with high perceptual fidelity. Our method operates in token space to capture semantic
structures more effectively and demonstrates superior results on long audio gaps compared to existing methods.
Model Overview
MusicNet Inpainting Results
Use headphones for best experience.
For each segment, we introduced four synthetic gaps at fixed, evenly spaced locations.
The gap durations varied across experiments, ranging from 50ms to 300ms.
These corrupted inputs were then processed using our model, which reconstructed the missing audio to produce complete, inpainted waveforms.